Abstract
Reconstructing animatable 3D human avatars from minimal visual input is a challenging task in digital human modeling and virtual content creation. Existing methods predominantly rely on multi-view observations or monocular videos, limiting their applicability in image-sparse scenarios. We introduce Photo2Avatar, a unified pipeline that reconstructs a 3D human avatar from a single image while supporting SMPL-X-driven animation. The method first synthesizes a dense set of multi-view images guided by parametric body priors, enabling spatially consistent supervision from a monocular portrait. A face-aware consistency enhancement module is then applied to improve identity preservation and cross-view coherence, particularly in facial regions. These refined views are used to supervise an animatable avatar learner under a differentiable rendering objective, allowing motion-conditioned geometry and appearance learning with minimal input. Extensive experiments demonstrate that Photo2Avatar achieves superior identity consistency, visual quality, and animation controllability compared to existing single-image baselines. The proposed method offers a practical solution for one-shot digital human reconstruction and bridges the gap between static image perception and dynamic 3D avatar animation.
Framework
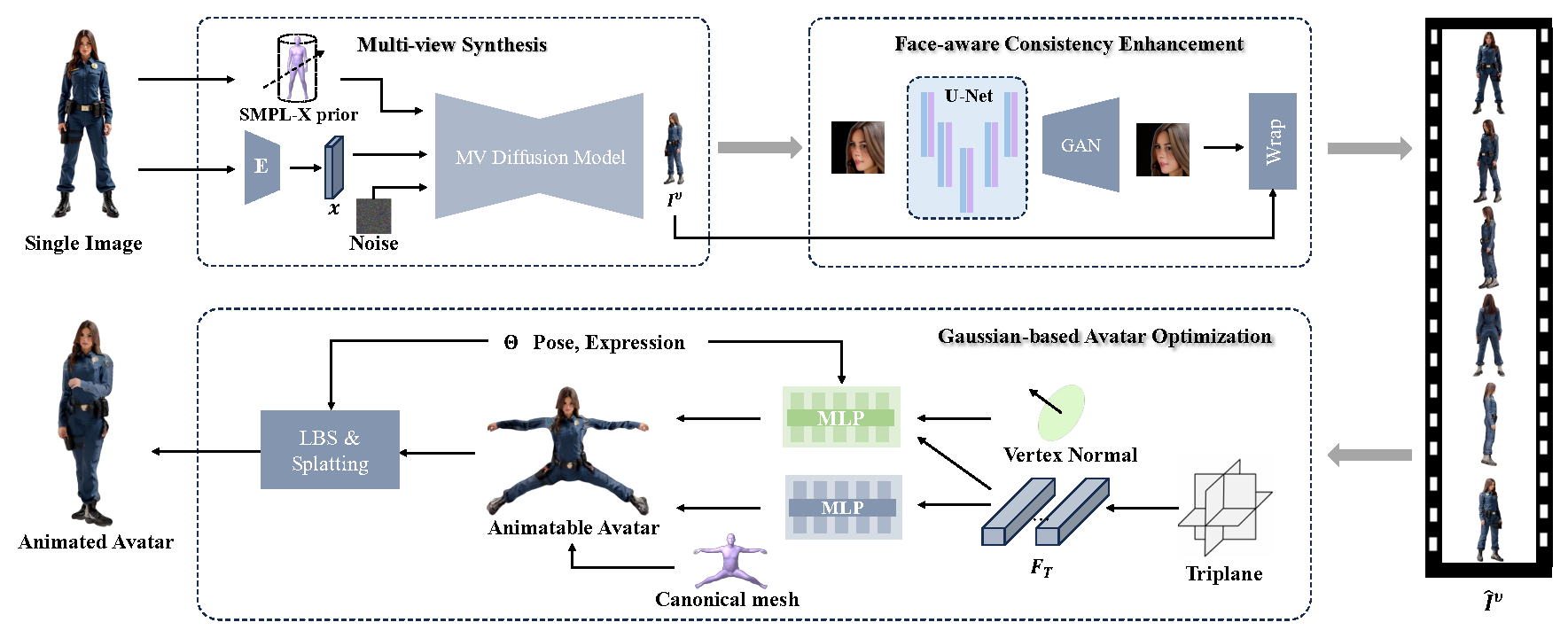
Overview of the Photo2Avatar framework. Starting from a single input image, the system synthesizes multi-view portraits guided by SMPL-X priors. A face-aware enhancement module improves cross-view identity consistency, and the enhanced views supervise the learning of a controllable 3D Gaussian avatar.